Build an All-Source Knowledge Assistant with Claude, RAG, Perplexity, and Drive
Categories
Created by
diPaulLast edited 205 days ago
📜 Detailed n8n Workflow Description
Main Flow
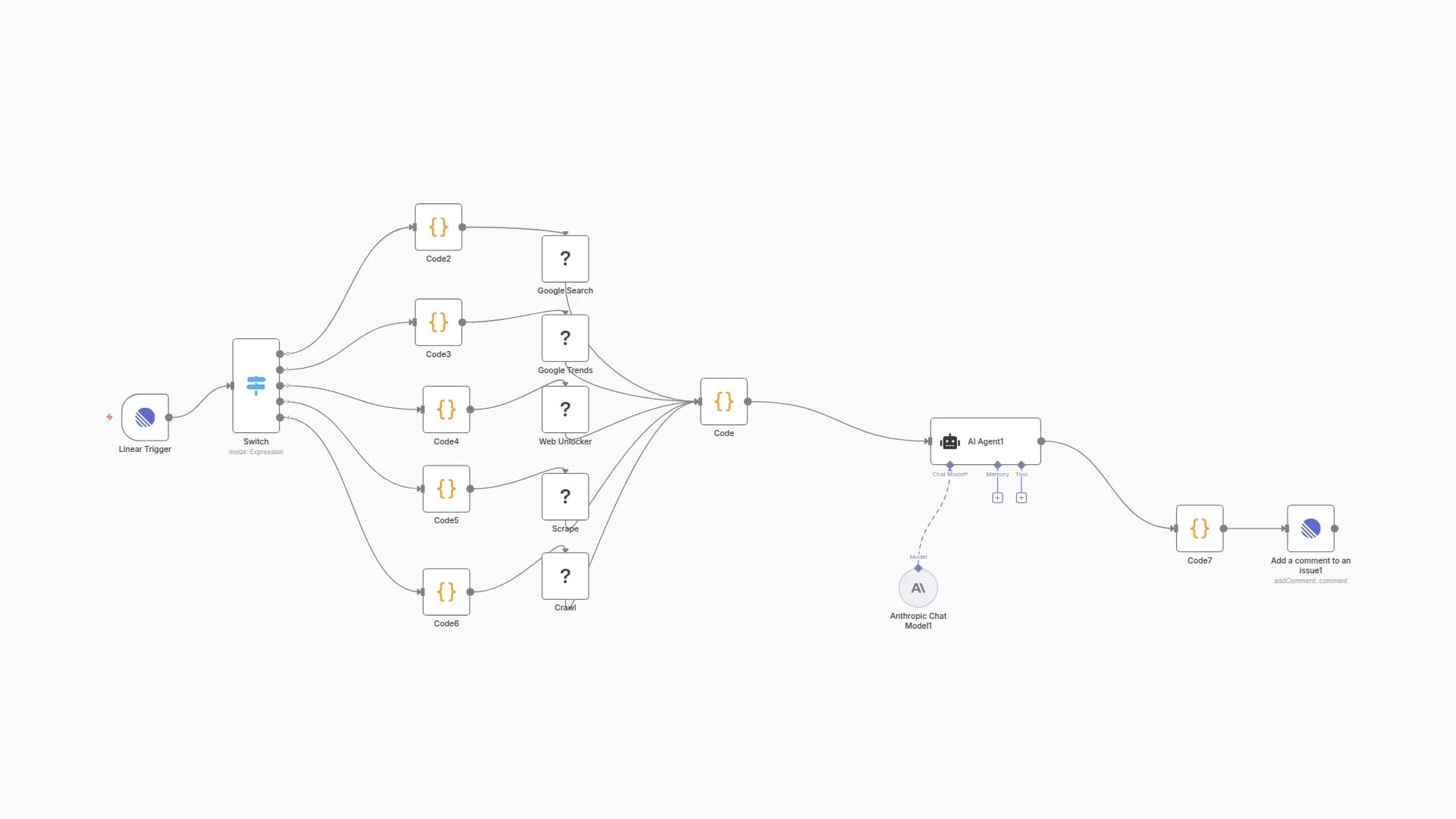
The workflow operates through a three-step process that handles incoming chat messages with intelligent tool orchestration:
-
Message Trigger: The
When chat message receivednode triggers whenever a user message arrives and passes it directly to theKnowledge Agentfor processing. -
Agent Orchestration: The
Knowledge Agentserves as the central orchestrator, registering a comprehensive toolkit of capabilities:- LLM Processing: Uses
Anthropic Chat Modelwith the claude-sonnet-4-20250514 model to craft final responses - Memory Management: Implements
Postgres Chat Memoryto save and recall conversation context across sessions - Reasoning Engine: Incorporates a
Thinktool to force internal chain-of-thought processing before taking any action - Semantic Search: Leverages
General knowledgevector store with OpenAI embeddings (1536-dimensional) and Cohere reranking for intelligent content retrieval - Structured Queries: Provides
structured dataPostgres tool for executing queries on relational database tables - Drive Integration: Includes
search about any doc in google drivefunctionality to locate specific file IDs - File Processing: Connects to
Read File From GDrivesub-workflow for fetching and processing various file formats - External Intelligence: Offers
Message a model in Perplexityfor accessing up-to-the-minute web information when internal knowledge proves insufficient
- LLM Processing: Uses
-
Response Generation: After invoking the
Thinkprocess, the agent intelligently selects appropriate tools based on the query, integrates results from multiple sources, and returns a comprehensive Markdown-formatted answer to the user.
Persistent Context Management
The workflow maintains conversation continuity through Postgres Chat Memory, which automatically logs every user-agent exchange. This ensures long-term context retention without requiring manual intervention, allowing for sophisticated multi-turn conversations that build upon previous interactions.
Semantic Retrieval Pipeline
The semantic search system operates through a sophisticated two-stage process:
- Embedding Generation:
Embeddings OpenAIconverts textual content into high-dimensional vector representations - Relevance Reranking:
Reranker Coherereorders search hits to prioritize the most contextually relevant results - Knowledge Integration: Processed results feed into the
General knowledgevector store, providing the agent with relevant internal knowledge snippets for enhanced response accuracy
Google Drive File Processing
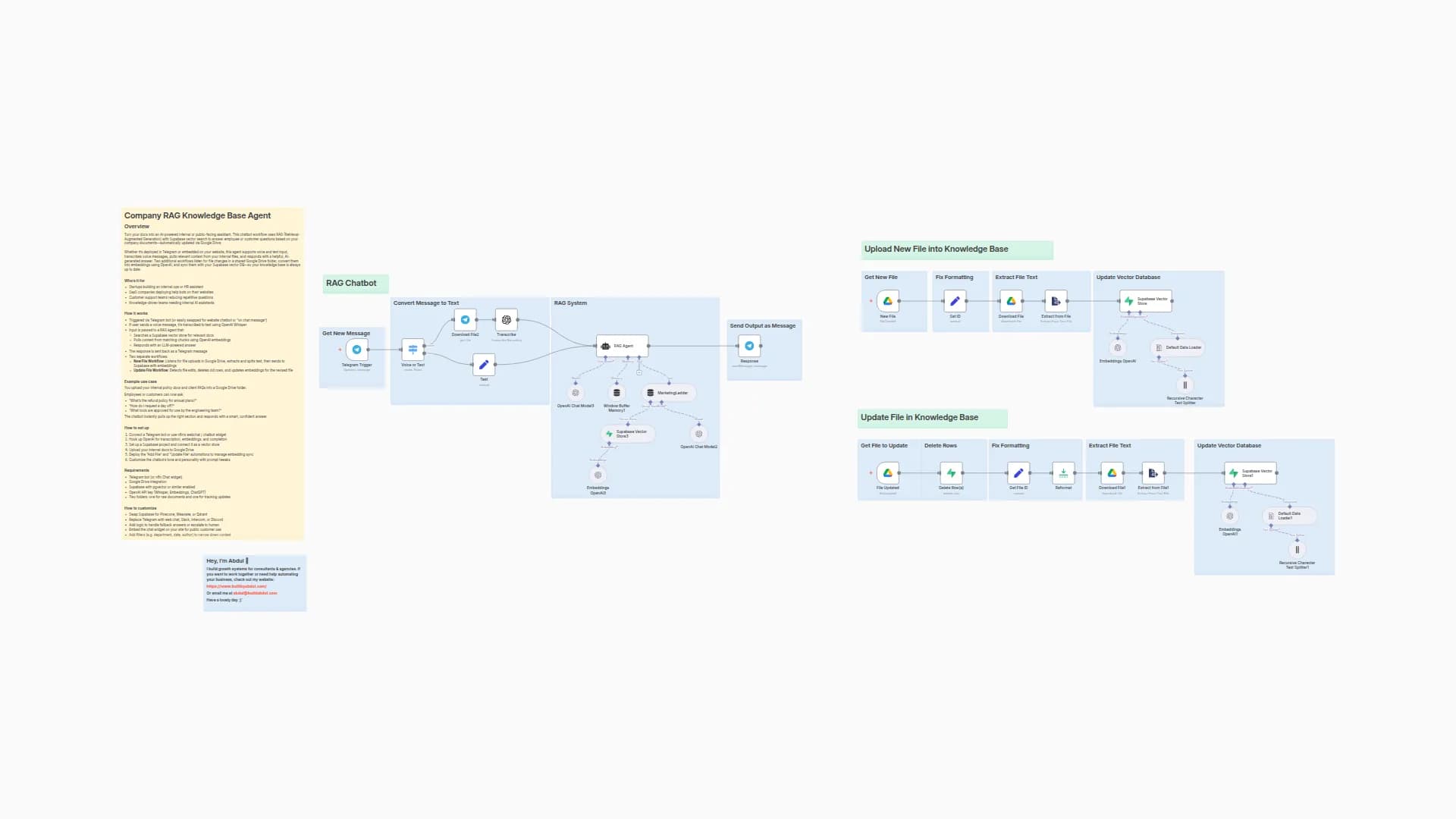
The file reading capability handles multiple formats through a structured sub-workflow:
- Workflow Initiation: The agent calls
Read File From GDrivewith the selectedfileIdparameter - Sub-workflow Activation:
When Executed by Another Workflownode activates the dedicated file processing sub-workflow - Operation Validation:
Operationnode confirms the request type isreadFile - File Retrieval:
Download File1node retrieves the binary file data from Google Drive - Format-Specific Processing:
FileTypenode branches processing based on MIME type:- PDF Files: Route through
Extract from PDF→Get PDF Responseto extract plain text content - CSV Files: Process via
Extract from CSV→Get CSV Responseto obtain comma-delimited text data - Image Files: Analyze using
Analyse Imagewith GPT-4o-mini to generate visual descriptions - Audio/Video Files: Transcribe using
Transcribe Audiowith Whisper for text transcript generation
- PDF Files: Route through
- Content Integration: The extracted text content returns to
Knowledge Agent, which seamlessly weaves it into the final response
External Search Capability
When internal knowledge sources prove insufficient, the workflow can access current public information through Message a model in Perplexity, ensuring responses remain accurate and up-to-date with the latest available information.
Design Highlights
The workflow architecture incorporates several key design principles that enhance reliability and reusability:
- Forced Reasoning: The mandatory
Thinkstep significantly reduces hallucinations and prevents tool misuse by requiring deliberate consideration before action - Template Flexibility: The design is intentionally generic—organizations can replace [your company] placeholders with their specific company name and integrate their own credentials for immediate deployment
- Documentation Integration: Sticky notes throughout the canvas serve as inline documentation for workflow creators and maintainers, providing context without affecting runtime performance
System Benefits
With this comprehensive architecture, the assistant delivers powerful capabilities including long-term memory retention, semantic knowledge retrieval, multi-format file processing, and contextually rich responses tailored specifically for users at [your company]. The system balances sophisticated AI capabilities with practical business requirements, creating a robust foundation for enterprise-grade conversational AI deployment.
You may also like

New to n8n?
Need help building new n8n workflows? Process automation for you or your company will save you time and money, and it's completely free!


