Build a PDF Q&A System with LlamaIndex, OpenAI Embeddings & Pinecone Vector DB
Last edited 206 days ago
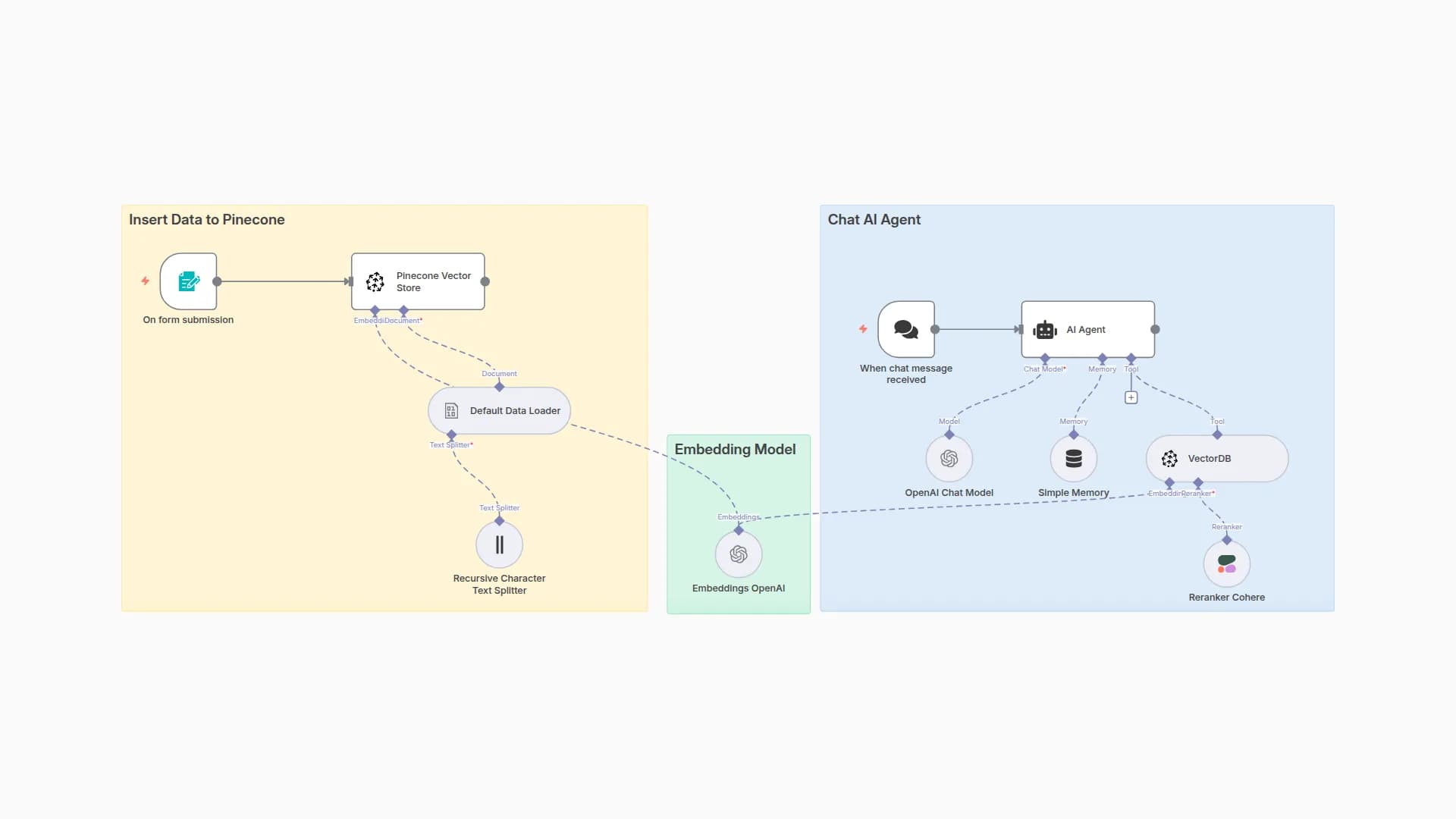
Parse, Normalize, Extract, and Store PDF Content for RAG in Pinecone
This workflow automates a full RAG pipeline for structured documents (like insurance policies).
What it does
- Watches a Google Drive folder for new PDFs
- Uploads to LlamaIndex Cloud for parsing → returns clean Markdown
- Normalizes text (removes headers, footers, page numbers, formatting artifacts)
- Splits text into chunks (~1200 chars with 150 overlap)
- Generates embeddings with OpenAI
- Stores vectors in Pinecone with metadata
- Connects a Chat Agent that retrieves answers from Pinecone
Who’s it for
- Developers building chatbots or Q&A systems for structured docs
- Teams working with insurance, compliance, or legal PDFs
- Anyone who needs to normalize & store documents for semantic search
Requirements
- Google Drive connected (for source PDFs)
- LlamaIndex Cloud account (parsing API key)
- Pinecone account (vector DB)
- OpenAI account (LLM and embeddings)
How to use and customize
- Update the folder name in google drive trigger node.
- Place a pdf file in the same folder in google drive.
- Customize the
Normalized Contentfunction node to adjust regex for headers/footers specific to your documents. - Adjust chunk size or metadata namespace in the Pinecone node to fit your project needs.
You may also like

New to n8n?
Need help building new n8n workflows? Process automation for you or your company will save you time and money, and it's completely free!


