Index Legal Documents for Hybrid Search with Qdrant, OpenAI & BM25
Last edited 206 days ago
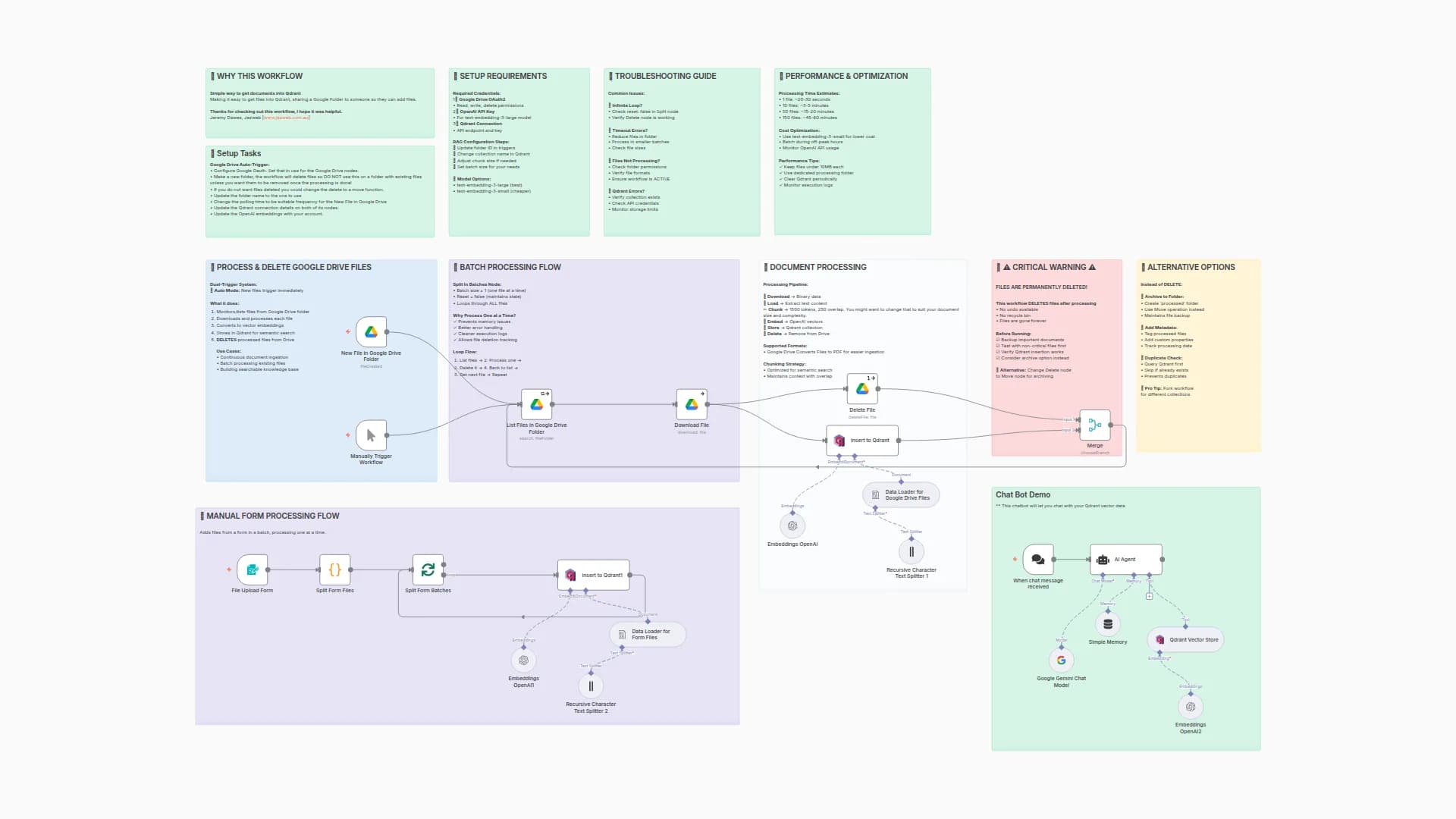
Index Legal Dataset to Qdrant for Hybrid Retrieval
This pipeline is the first part of "Hybrid Search with Qdrant & n8n, Legal AI".
The second part, "Hybrid Search with Qdrant & n8n, Legal AI: Retrieval", covers retrieval and simple evaluation.
Overview
This pipeline transforms a Q&A legal corpus from Hugging Face (isaacus) into vector representations and indexes them to Qdrant, providing the foundation for running Hybrid Search, combining:
- Dense vectors (embeddings) for semantic similarity search;
- Sparse vectors for keyword-based exact search.
After running this pipeline, you will have a Qdrant collection with your legal dataset ready for hybrid retrieval on BM25 and dense embeddings: either mxbai-embed-large-v1 or text-embedding-3-small.
Options for Embedding Inference
This pipeline equips you with two approaches for generating dense vectors:
- Using Qdrant Cloud Inference, conversion to vectors handled directly in Qdrant;
- Using external provider, e.g. OpenAI for generating embeddings.
Prerequisites
- A cluster on Qdrant Cloud
- Paid cluster in the US region if you want to use Qdrant Cloud Inference
- Free Tier Cluster if using an external provider (here OpenAI)
- Qdrant Cluster credentials:
- You'll be guided on how to obtain both the URL and API_KEY from the Qdrant Cloud UI when setting up your cluster;
- An OpenAI API key (if you’re not using Qdrant’s Cloud Inference);
P.S.
- To ask retrieval in Qdrant-related questions, join the Qdrant Discord.
- Star Qdrant n8n community node repo <3
You may also like

New to n8n?
Need help building new n8n workflows? Process automation for you or your company will save you time and money, and it's completely free!


